Rights Versus Liberation
Classifying Subreddit Posts with Natural Language Processing
Project 3: Subreddit Classification with NLP¶
Introduction & Problem Statement¶
Machine learning has come a pretty long way, especially in the area of Natural Language Processing (NLP), which is a branch of artificial intelligence that can help computers understand, interpret and manipulate human language. With the steadily increasing amounts of unstructured data growing every day, automation is becoming vital in analyzing text and speech data efficiently.
This is relevant to social media websites like Reddit - a collection of interest-based communities known as subreddits - that are growing in popularity but face management issues and bottlenecks due to the limited availability of human moderators. Reddit can also be overwhelming to new users, who may struggle to find the right subreddit as subreddit names can be highly misleading. This project aims to solve this problem through a subreddit post classifier.
Problem statement: How can NLP be best used to classify posts from two different subreddits based on their title and text content?
For this project, I selected two subreddits that are ostensibly similar on the surface -- r/MensLib and r/MensRights. Both subreddits focus mainly on male issues such as suicide or homelessness, and both give men a space to discuss their beliefs around gender rights and issues. The main difference between these subreddits is that r/MensLib has a broad definition of masculinity and supports feminism, while r/MensRights generally has a narrower definition of masculinity and is driven by the idea that feminism/feminists are actively harming men. Furthermore, they believe that there is serious discrimination against men inherent in western societies.
While the moderation teams of both subreddits could benefit from having some kind of classification tool, r/MensLib would likely benefit much more from a NLP classifier, given their strict moderation policies. I also personally believe that the positions of both these subreddits are worth deeper examination. r/MensLib is generally believed to have a more 'positive' community than r/MensRights, but is this really the case? Are the topics they discuss similar, or different?
The full code for this project is available here.
Data Scraping¶
To get at the posts we need, we have to decide on a way to scrape them. There are various methods for scraping data, but the most straightforward way is to look for the Application Programming Interface (API) of a site and extract a JavaScript Object notation (JSON), if available. This .JSON can be then read into Python as a dictionary using the json module.
Luckily, Reddit allows us to access the JSON of each subreddit that gives us access to the top-ranked 1000 posts. Off the bat, I knew that I wanted to track the volume of posts in each Reddit, which means that I would have to find another method to scrape that much data. Additionally, I wanted more infomation such as the number of upvotes and comments that each post had.
To accomplish this, I took a dual approach. I used the Python Reddit API Wrapper (PRAW) - a third-party tool - to extract 1000 of the most popular posts from each subreddit and the PushShift API (PSAW) to extract all posts between Aug 1 and Nov 28.
This allowed me to capture the following information:
- All posts from each subreddit between Aug 1 - Nov 28
- 1000 top posts from each subreddit including:
- Date of post
- Title of post
- Text within post
- Number of upvotes
- Upvote ratio
- Number of comments
- Type of post (moderator/non-moderator post)
- Permalink
- Author of post
Data Cleaning¶
Now that we have our data, the key question now is what to do with it, or how to make it interpretable to our computers. Because the text we just gathered is unstructured data, we need to make sure that our text is clean and free of null values or duplicated entries. This entails removing URL links and non-alphanumerical characters that won't be useful in a classification model.
# 75 mod posts vs 0 posts
menslib['distinguished'].isin(['moderator']).sum(), mensrights['distinguished'].isin(['moderator']).sum()
# Deal with null values
menslib['selftext'] = menslib['selftext'].fillna('')
mensrights['selftext'] = mensrights['selftext'].fillna('')
# Check for duplicates
duplicates = menslib[(menslib.duplicated(subset=['selftext'])) & (menslib['selftext'] != '')] \
.sort_values(ascending=False, by='selftext') \
['title'].value_counts()
duplicates.head(4)
# No duplicates!
mensrights[(mensrights.duplicated(subset=['selftext'])) & (mensrights['selftext'] != '')] \
.sort_values(ascending=False, by='selftext')['title'].value_counts()
menslib = menslib.drop_duplicates(subset=['title'])
# Check for any more duplicates
duplicates = menslib[(menslib.duplicated(subset=['selftext'])) & (menslib['selftext'] != '')] \
.sort_values(ascending=False, by='selftext') \
['title'].value_counts()
duplicates
# Dropping weekly threads that are mod posts
menslib = menslib.drop(menslib[menslib['title'].str.contains('Weekly Free Talk')].index)
menslib = menslib.drop(menslib[menslib['title'].str.contains('Tuesday Check')].index)
menslib = menslib.drop(menslib[menslib['title'].str.contains('NEW Resources of The Week Highlight')].index)
To conduct further analysis in areas such as word and ngram frequency, we'll first have to clean the data by removing http links and irrelevant non-alpha-numeric characters.
def drop_links(text):
words = text.split(' ')
words_to_sub = [w for w in words if 'http' in w]
if words_to_sub:
for w in words_to_sub:
new_word = re.sub('http.*', '', w)
text = re.sub(w, new_word, text)
return text
# If no links in post, return text
return text
After data scraping, I found that a few posts had HTML tags and emoticons that needed slightly more specialized treatment. For example, ​ which is the HTML character for a zero width space can't be dealt with simply by removing non alpha-numeric characters, we'll still end up with 'xb' which is not what we want. Here, we'll use RegEx to remove unwanted HTML.
def preprocessing(text):
# Remove new lines
text = text.replace('\n',' ').lower()
# Remove emoticons
text = re.sub(':d', '', str(text)).strip()
text = re.sub(':p', '', str(text)).strip()
# Remove HTML markers and punctuation
text = re.sub('xa0', '', str(text)).strip()
text = re.sub('x200b', '', str(text)).strip()
text = re.sub('[^a-zA-Z\s]', '', str(text)).strip()
return text
# Removing new lines, removing punctuation and tokenizing text for menslib
menslib['cleaned_title'] = menslib['title'].apply(preprocessing)
menslib['cleaned_selftext'] = menslib['selftext'].apply(preprocessing)
# Removing new lines, removing punctuation and tokenizing text for mensrights
mensrights['cleaned_title'] = mensrights['title'].apply(preprocessing)
mensrights['cleaned_selftext'] = mensrights['selftext'].apply(preprocessing)
# Dropping links
menslib['cleaned_selftext'] = menslib['cleaned_selftext'].apply(drop_links)
mensrights['cleaned_selftext'] = mensrights['cleaned_selftext'].apply(drop_links)
# Combining title and selftext
menslib['combi_text'] = menslib['cleaned_title'] + ' ' + menslib['cleaned_selftext']
mensrights['combi_text'] = mensrights['cleaned_title'] + ' ' + mensrights['cleaned_selftext']
Lemmatization¶
It's worth noting here that I also tried out lemmatization, which helps to reduce inflectional forms and derivationally related forms of a word to a common base form. I ultimately didn't use lemmatization however, as it led to a decreased level of accuracy during model testing. There's also existing research out there has generally shown that lemmatization is not necessary, especially for languages with a simple morphology like English. Given that we're trying to classify posts, even small differences in language could make a large difference regarding the accuracy of our model.
# Comparing lemmatized vs regular text
# We can see that a lot of nuance within the post has been lost after lemmatization and removal of stop words
print(menslib['combi_text'][0], '\n')
print(menslib['lem_combi_text'][0])
def plotter_1(column):
fig, ax = plt.subplots(1, 2, figsize=(12,6), sharey=True)
ax = ax.ravel()
g1 = sns.histplot(data=menslib, x=column, ax = ax[0], bins=20)
mean_1 = menslib[column].mean()
g1.set_title(f'r/MensLib (Mean: {round(mean_1)} {column})')
ax[0].axvline(mean_1, ls='--', color='black')
g2 = sns.histplot(data=mensrights, x=column, ax = ax[1], bins=20, color='darkorange')
mean_2 = mensrights[column].mean()
g2.set_title(f'r/MensRights (Mean: {round(mean_2)} {column})')
ax[1].axvline(mean_2, ls='--', color='black')
plt.suptitle(f'{column.capitalize()}', fontsize=20)
plt.tight_layout()
plotter_1('upvotes')

While both subreddits have a large number of posts that have less than 2000 upvotes, the majority of posts from r/MensRights have less than 1,000 upvotes. We can see that posts in r/MensLib are more evenly distributed, though still skewed towards the right. r/MensRights has an outlier post that reached over 20,000 upvotes.
mensrights[mensrights['upvotes'] > 20_000]
This post is likely to have made it to the front page of Reddit and resonated with readers there. Public sentiment of Johnny Depp has been mostly positive since the trial, with many redditors upset over Johnny Depp's treatment by the media and companies like Disney. This is a rallying issue for r/MensRights, which focuses heavily on false accusations of rape or sexual assault made against men.
plotter_1('n_comments')
plt.suptitle('Number of Comments', fontsize=18)

The community of r/MensLib seems to be a lot more active than that of r/MensRights, despite the higher subscriber count of the latter.
Summary of Differences¶
'Hot' or popular posts from r/MensRights have an average of 233 upvotes, with around 25 comments per post. In comparison, posts from r/MensLib have an average of 595 upvotes, and 91 comments per post. Based on this, it seems that the r/MensLib community is a lot more active.
However, it's worth noting that r/MensRights has 286,000 subscribers compared to the 152,000 subscribers of r/MensLib, so we can't base popularity off these statistics alone.
Exploratory Data Analysis¶
fig, ax = plt.subplots(1, 2, figsize=(12,6), sharey=True)
ax = ax.ravel()
g1 = sns.countplot(data=menslib, x=menslib['is_self'].astype(int), ax = ax[0], palette='Blues')
g1.set_xticklabels(['Image Post', 'Text Post'])
g1.set_title('r/MensLib', fontsize=16)
g1.set_xlabel('')
g2 = sns.countplot(data=mensrights, x=mensrights['is_self'].astype(int), ax = ax[1], palette='Oranges')
g2.set_xticklabels(['Image Post', 'Text Post'])
g2.set_title('r/MensRights', fontsize=16)
g2.set_ylabel('')
g2.set_xlabel('')
plt.suptitle('Type of Post', fontsize=20)
plt.tight_layout()

A large number of posts in r/MensRights are not text posts. R/MensLib also has a substantial number of non-text posts. As we created a feature that combines both title text and post text (combi_text), this shouldn't pose much of an issue to our model later on.
def subplot_histograms(col, graph_title):
fig, ax = plt.subplots(1, 2, figsize=(12,6), sharey=True)
ax = ax.ravel()
# Plot first df
g1 = sns.histplot(data=menslib, x=menslib[col].str.len(), ax = ax[0], bins=25)
mean_1 = menslib[col].str.len().mean()
ax[0].axvline(mean_1, ls='--', color='black')
g1.set_title(f'r/MensLib (Mean: {round(mean_1)} words)')
g1.set_xlabel(f'Length of {col.capitalize()}')
# Plot second df
g2 = sns.histplot(data=mensrights, x=mensrights[col].str.len(), ax = ax[1], bins=25, color='darkorange')
mean_2 = mensrights[col].str.len().mean()
ax[1].axvline(mean_2, ls='--', color='black')
g2.set_title(f'r/MensRights (Mean: {round(mean_2)} words)')
g2.set_xlabel(f'Length of {col.capitalize()}')
plt.suptitle(graph_title, fontsize=20)
plt.tight_layout()
subplot_histograms('title', 'Average Title Length')

r/MensLib generally has slightly shorter title lengths than r/MensRights, but the average post length in r/MensLib is much greater than the average post length in r/MensRights. The differences here could make these features useful for our classifier model.
Analyzing Ngrams¶
To analyze the language within each subreddit, I took a bag-of-words approach, where each word is broken into units (or tokenized) and counted according to how often this given word appears in a post.
This approach is called a 'bag' of words, because any information about the order or structure of words in the document is discarded. The model is only concerned with whether known words occur in the document, not where in the document. Within this process, we'll also look to remove frequent words that don’t contain much information, like 'a,' 'of,' etc. These are known as stop words.
To do this, we'll be using CountVectorizer(), a scikit-learn tool that helps to both tokenize a collection of text documents and build a vocabulary of known words and encode new documents using that vocabulary. We'll also be using it to exclude stopwords from our results.
# Create function to get top words
def plot_top_words(df, col, n, n_gram_range, title, palette='tab10'):
def get_top_n_words(corpus, n=n, k=n_gram_range):
vec = CountVectorizer(ngram_range=(k,k), stop_words='english').fit(corpus)
bag_of_words = vec.transform(corpus)
sum_words = bag_of_words.sum(axis=0)
words_freq = [(word, sum_words[0, idx]) for word, idx in vec.vocabulary_.items()]
words_freq =sorted(words_freq, key = lambda x: x[1], reverse=True)
return words_freq[:n]
temp_df = pd.DataFrame(data=get_top_n_words(df[col], n), columns=['word','freq'])
plt.figure(figsize=(10,6))
sns.barplot(data=temp_df, y='word', x='freq', palette=palette)
plt.ylabel('')
plt.xlabel('')
plt.title(title, fontsize=18)
plot_top_words(menslib,'cleaned_title', 10, 1, 'r/menslib Top 10 Words', 'Blues_r')

stop_words = set(CountVectorizer(stop_words = 'english').get_stop_words())
The full code for the data scraping process can be found here.
plot_top_words(mensrights,'cleaned_title', 10, 1, 'r/mensrights Top 10 Words', 'Reds_r')

There's a large amount of overlap between the top words in r/MensRights and r/MensLib as expected. Namely, the focus on various male nouns e.g. men, mens, male, man. However, there's a much stronger focus on masculinity within r/MensLib. The subreddit also encompasses the issues of children, and focuses on issues affecting the physical and emotional health of men.
Within r/MensRights, the focus is much more topical. Topics that are common in the sub include the celebration of International Men's Day and the Johnny Depp & Amber Heard court case.
Top Bigrams¶
plot_top_words(menslib,'cleaned_selftext', 10, 2, 'r/menslib Top Bigrams', palette='Blues_r')

plot_top_words(mensrights,'cleaned_selftext', 10, 2, 'r/mensrights Top Bigrams', palette='Reds_r')

The relationship between men and women is an important topic in each subreddit, though we can now see more of the key differences based on the bigrams. The bigrams used within r/MensLib (e.g. don't know, don't think, don't want) along with their frequency (>40) are a likely indicator that the community is somewhat introspective.
For r/MensRights, key topical issues include men paying child support and sexual discrimination (Title IX is a US federal law that prohibits discrimination based on sex). Men's rights activists believe that Title IX is an unfair law that denies proper due process and is a tool that is used indiscriminantly against men.
Top Trigrams¶
plot_top_words(menslib, 'cleaned_selftext', 10, 3, 'r/menslib Top Trigrams', 'Blues_r')

plot_top_words(mensrights,'cleaned_selftext', 10, 3, 'r/mensrights Top Trigrams', palette='Reds_r')

The focus on the emotional health of men is quite clear within r/MensLib. The frequent use of pronouns within the trigrams also suggests that personal issues and viewpoints are commonly discussed within the subreddit. In comparison, the trigrams for r/MensRights are factual and once again topical.
International Men's Day also seems to be a huge topic for r/MensRights. Within r/MensLib, the moderation team created a single post that fulfilled the purpose of celebrating International Men's Day, which is why we don't see mentions of it within our bigrams or trigrams.
Feminism as a movement seems to be also quite negatively viewed within the subreddit. This alludes to differences in sentiment between both subreddits that we'll explore further down.
Analyzing Volume of Posts¶
fig, ax = plt.subplots(1, 1, figsize=(16,8))
menslib_vdf['date'].value_counts().plot()
mensrights_vdf['date'].value_counts().plot()
plt.xlabel('Date')
plt.ylabel('Number of Posts')
plt.title('Overall Post Volume (Aug 2020 - Dec 2020)', fontsize=18)
legend = plt.legend(title='Subreddit', loc='best', labels=['r/MensLib', 'r/MensRights'], fontsize=12)
legend.get_title().set_fontsize('12')

The difference between the number of posts within each subreddit is quite obvious here. While arguably r/MensLib has higher 'quality' posts (as indicated by higher upvotes and number of comments), r/MensRights has people posting much more frequently. This could be due to the strict moderation policy of r/MensLib which discourages users from making low-quality posts.
# There was a noticeable spike in posts from Nov 19 - Nov 21 -- this was likely due to International Men's Day on 19 Nov
mensrights_vdf['date'].value_counts().head()
Deleted Posts¶
fig, ax = plt.subplots(1, 1, figsize=(16,8))
menslib_vdf['date'].value_counts().plot(color='dodgerblue')
menslib_vdf[(menslib_vdf['selftext'] == '[removed]') & (menslib_vdf['n_comments'] < 3)] \
['date'].value_counts().plot(color='lightgrey')
plt.title('r/MensLib: Deleted Posts versus Actual Posts', fontsize=18)
plt.ylabel('Post Frequency')
plt.ylim(0, 60)
legend = plt.legend(title='Post Type', loc='best', labels=['Regular (r/MensLib)', 'Deleted'], fontsize=12)
legend.get_title().set_fontsize('12')

fig, ax = plt.subplots(1, 1, figsize=(16,8))
mensrights_vdf['date'].value_counts().plot(color='darkorange')
mensrights_vdf[(mensrights_vdf['selftext'] == '[removed]') & (mensrights_vdf['n_comments'] < 3)] \
['date'].value_counts().plot(color='lightgrey')
plt.title('r/MensRights: Deleted Posts versus Actual Posts', fontsize=18)
plt.ylabel('Post Frequency')
legend = plt.legend(title='Post Type', loc='best', labels=['Regular (r/MensRights)', 'Deleted'], fontsize=12)
legend.get_title().set_fontsize('12')

Within the posts that we scraped with PSAW from r/MensLib, a large number of these posts are either posts that have been deleted or removed. This is due to strict automoderation policy, as well as active efforts on the part of moderators to prevent the subreddit from being flooded with irrelevant content. In comparison, r/MensRights has a lot less removed/deleted posts. This could be due to more lenient moderation.
Preparation for Sentiment Analysis¶
# Setting up target column
menslib['is_menslib'] = 1
mensrights['is_menslib'] = 0
combined_df['og_text'] = combined_df['title'] + '\n\n' + combined_df['selftext']
# Final check for null values
combined_df.isnull().sum()[combined_df.isnull().sum() > 0]
combined_df.to_csv('./datasets/combined_df.csv', index=False)
Sentiment Analysis¶
There seems to be a clear difference in sentiment between both subreddits, both how can we prove this? In the NLP field, there are various tools that try to gauge sentiment. The tool that I'm using is the NLTK sentiment analyzer, also known as VADER (Valence Aware Dictionary and sEntiment Reasoner), which is a lexicon (dictionary of sentiments in this case) and a simple rule-based model for general sentiment analysis.
VADER is able to give us a Positivity and Negativity score that can be standardized in a range of -1 to 1. VADER is able to include sentiments from emoticons (e.g, :-D), sentiment-related acronyms (e.g, LoL) and slang (e.g, meh) where algorithms typically struggle. This makes it a good fit for the casual language that's being used across both subreddits.
sentiment_df = combined_df[['combi_text', 'og_text', 'is_menslib']].reset_index(drop=True)
By calling the SentimentIntensityAnalyzer() on each post, we can retrieve the proportion of text that falls in the negative, neutral or positive category. From this, we can also retrieve the compound score of each post, which is a metric that calculates the sum of all the lexicon ratings which have been normalized between -1 and 1. In short, compound scores are the sum of valence computed based on internal heuristics and a sentiment lexicon.
Based on the compound score, we can then create a categorical feature - comp_score - that reflects whether a post is overall positive or negative based on compound score.
# Initialise VADER
sid = SentimentIntensityAnalyzer()
# Analyzing sentiment with VADER
sentiment_df['scores'] = sentiment_df['combi_text'].apply(lambda x: sid.polarity_scores(x))
sentiment_df['compound'] = sentiment_df['scores'].apply(lambda score_dict: score_dict['compound'])
sentiment_df['comp_score'] = sentiment_df['compound'].apply(lambda c: 'pos' if c >=0 else 'neg')
sentiment_df['subreddit'] = sentiment_df['is_menslib'].apply(lambda x: 'r/MensLib' if x == 1 else 'r/MensRights')
sentiment_df.head()
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
ax = ax.ravel()
sns.histplot(sentiment_df[sentiment_df['is_menslib'] == 1]['compound'].values, ax = ax[0])
sns.histplot(sentiment_df[sentiment_df['is_menslib'] == 0]['compound'].values, color='darkorange', ax = ax[1])
mean_1 = sentiment_df[sentiment_df['is_menslib'] == 1]['compound'].mean()
mean_2 = sentiment_df[sentiment_df['is_menslib'] == 0]['compound'].mean()
ax[0].set_title(f'r/MensLib (Mean: {(mean_1):.2f})', fontsize=18)
ax[1].set_title(f'r/MensRights (Mean: {(mean_2):.2f})', fontsize=18)
ax[0].axvline(mean_1, ls='--', color='black')
ax[1].axvline(mean_2, ls='--', color='black')
ax[0].set_xlabel('Sentiment')
ax[0].set_ylabel('Word Frequency')
ax[1].set_xlabel('Sentiment')
ax[1].set_ylabel('')
plt.suptitle('Sentiment Analysis', fontsize=20);

Our initial hypothesis seems to have been largely correct -- the sentiment within r/MensLib seems to be much more positive. Most posts tend towards the right side of the graph, with a large number of posts having a high positive sentiment score between 0.8 and 1.0. In comparison, r/MensRights has a large number of posts that are strongly negative, and relatively fewer posts that are strongly positive.
# We can also see that the average sentiment within r/MensLib is much higher.
sentiment_df[sentiment_df['is_menslib']==1]['compound'].mean(), sentiment_df[sentiment_df['is_menslib']==0]['compound'].mean()
# Example of a strongly negative post within r/MensLib.
# As a whole, this post isn't actually 'negative' despite the negative sentiment that VADER is detecting.
temp_df = sentiment_df[(sentiment_df['subreddit'] == 'r/MensLib')
& (sentiment_df['compound'] < -0.9)]['og_text'].reset_index()
print(temp_df['og_text'][6])
# Example of a strongly negative or 'angry' post within r/MensRights.
temp_df2 = sentiment_df[(sentiment_df['subreddit'] == 'r/MensRights')
& (sentiment_df['compound'] < -0.9)]['og_text'].reset_index()
print(temp_df2['og_text'][17])
Sentiment Visualization with Scattertext¶
To get a better grasp of the words and the sentiment behind them across both subreddits, we'll use a tool called Scattertext. Scattertext can help visualize what words and phrases are more characteristic of a category than others. Below, we'll try to visualize sentiment across both subreddits and see what are the most 'positive' and 'negative' words.
Scattertext uses scaled f-score (the harmonic mean between precision and recall), which takes into account category-specific precision and term frequency when ranking words. A detailed explanation of the formula behind scaled f-score can be found here.
In this case, we'll be looking to compare positive and negative sentiment posts based on our sentiment scores created through VADER. While a word may appear frequently in either the negative or positive category, Scattertext can use scaled f-score to detect whether a particular term is more characteristic of a particular category.
nlp = spacy.load('en')
# Build corpus for Scattertext sentiment analysis
corpus = st.CorpusFromPandas(sentiment_df, category_col='comp_score', text_col='combi_text', nlp=nlp).build()
html = st.produce_scattertext_explorer(corpus,
category='pos',
category_name='Positive',
not_category_name='Negative',
width_in_pixels=1000,
metadata=sentiment_df['subreddit'],
save_svg_button=True)
html_file_name = "Project_3_Sentiment_Analysis.html"
open(html_file_name, 'wb').write(html.encode('utf-8'))
The blue dots represent words that have been ranked as positive, while the red dots represent words that have been ranked as negative. As a general observation, the words in blue seem to be used more frequently within r/MensLib, while the words in red are used more frequently within r/MensRights.
As an example of how ScatterText works take the word 'feminist'. While the word is frequent across both 'negative' and 'positive' categories, Scattertext concludes that 'feminist' belong in the 'negative' category due to it's scaled f-score of -0.1. This means that the word generally appears more in negative posts than positive posts.
The interactive version of this chart can be viewed within your browser here.
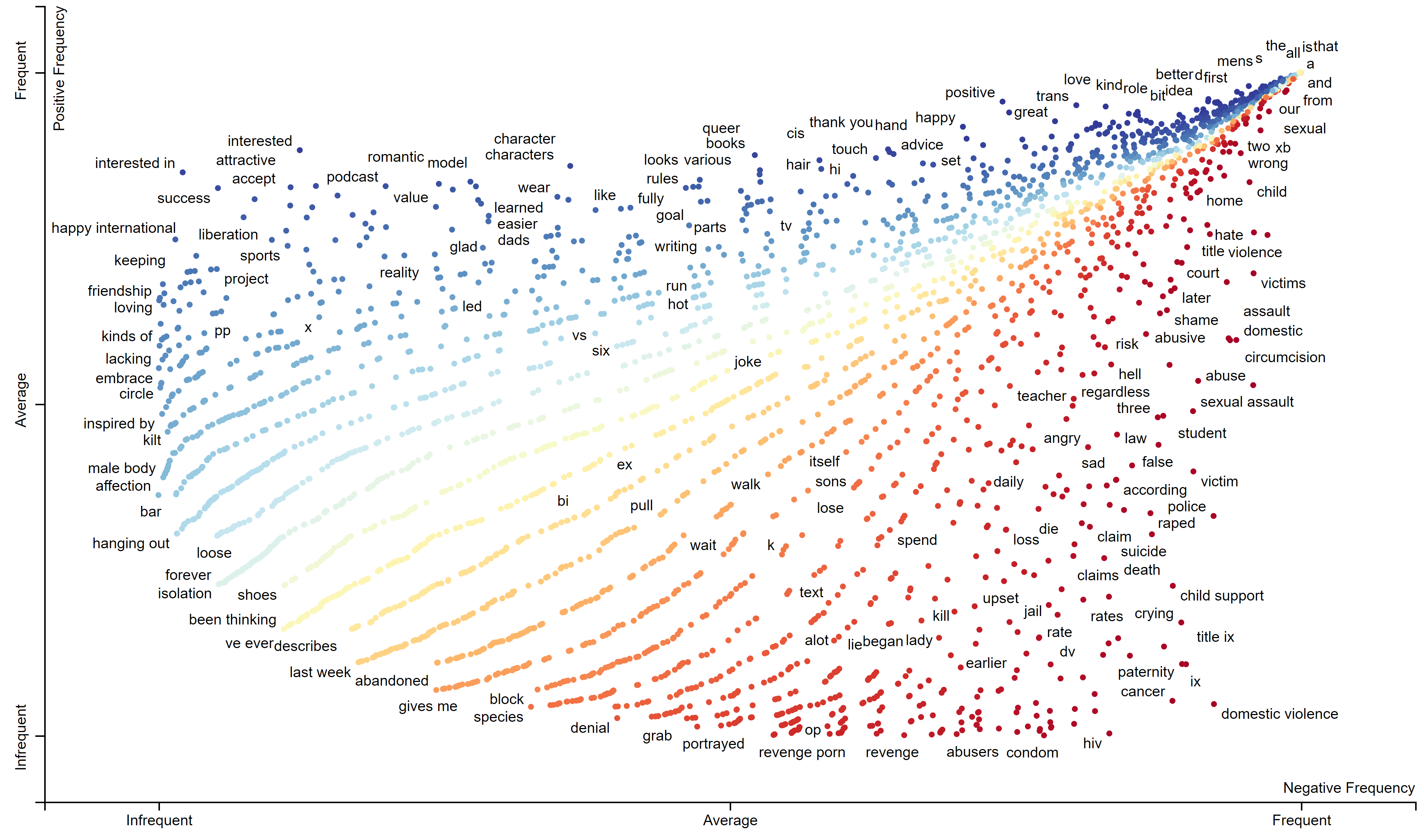
We can think of this particular map as a sentiment analysis chart of gender issues facing men. While this chart isn't perfect, it reveals some interesting insights in terms of what both subreddits talk about. Words like fatherhood, male friendship and role models appear on the positive side of the spectrum, while words like sexual assault, victim and domestic violence appear on the negative end of the spectrum.
sentiment_df['is_menslib'].corr(sentiment_df['compound'])
We can see that clearly, a correlation does exist between sentiment and whether a post comes from either r/MensLib or r/MensRights. We've proved our initial hypothesis that r/MensLib is a more 'positive' community - as is_menslib increases from 0 (r/MensRights) to 1 (r/MensLib), sentiment scores tend to increase.
We've also seen that VADER is limited in being able to understand words that have a negative connotation versus a post with negative words but overall positive sentiment.
Model Selection¶
The next step that we'll cover below is selecting and tuning a model that can help predict where each post comes from. This is, in effect, a binary classification problem. To find the best model to use here, we'll carry out the following steps:
- Run a Train-Test-Split on our data
- Transform data using a vectorizer
- Fit model to training data
- Generate predictions using test data
- Evaluate model based on various evaluation metrics (accuracy, precision, recall, ROC-AUC).
- Select the best model and tune hyper-parameters
Besides CountVectorizer(), we'll also be using TfidfVectorizer(). TfidfVectorizer() is pretty similar to CountVectorizer, except that it looks at the frequency of words in our data. This means that it downweights words that appear in many posts, while upweighting the rarer words.
We'll look to test a range of classification techniques including Logistic Regression, Random Forest, Boosting, Multinomial Naive Bayes classification and Support Vector Machine (SVM) classification.
Accuracy and F-score will be our main metrics here, given that we're not too particularly concerned about minimizing either false negatives and false positives -- ideally we'd like to minimize both as far as possible.
Baseline Model¶
To have something to compare our model against, we can use the normalized value of y, or the percentage of y within our target. This represents the simplest model we can use, where assigning a post randomly will give us a 53.4% chance of classifying it correctly.
# Baseline
y = combined_df['is_menslib']
y.value_counts(normalize=True)
Train Test Split¶
I chose not to drop particular stopwords here like 'men, rights, lib/liberal, menslib' as I felt both subreddits were likely to discuss these topics independently. My examination of the data also didn't reveal any of these labels as a dead giveaway.
X = combined_df['combi_text']
y = combined_df['is_menslib']
# Split our data into train and test data. We're stratifying here to ensure that the train and test sets
# have approximately the same percentage of samples in order to avoid imbalanced classes.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y, random_state=42)
Model Preparation¶
Here, I instantiated a range of different vectorizers and models. To simplify my workflow slightly, I opted to create a function that utilizes Sklearn's Pipeline tool that allows for easy fitting and transformation of data.
# Instantiate vectorizers
vectorizers = {'cvec': CountVectorizer(),
'tvec': TfidfVectorizer(),
'hv': HashingVectorizer()}
# Instiantiate models
models = {'lr': LogisticRegression(max_iter=1_000, random_state=42),
'rf': RandomForestClassifier(random_state=42),
'gb': GradientBoostingClassifier(random_state=42),
'et': ExtraTreesClassifier(random_state=42),
'ada': AdaBoostClassifier(random_state=42),
'nb': MultinomialNB(),
'svc': SVC(random_state=42)}
# Function to run model -- input vectorizer and model
def run_model(vec, mod, vec_params={}, mod_params={}, grid_search=False):
results = {}
pipe = Pipeline([
(vec, vectorizers[vec]),
(mod, models[mod])
])
if grid_search:
gs = GridSearchCV(pipe, param_grid = {**vec_params, **mod_params}, cv=5, verbose=1, n_jobs=-1)
gs.fit(X_train, y_train)
pipe = gs
else:
pipe.fit(X_train, y_train)
# Retrieve metrics
results['model'] = mod
results['vectorizer'] = vec
results['train'] = pipe.score(X_train, y_train)
results['test'] = pipe.score(X_test, y_test)
predictions = pipe.predict(X_test)
results['roc'] = roc_auc_score(y_test, predictions)
results['precision'] = precision_score(y_test, predictions)
results['recall'] = recall_score(y_test, predictions)
results['f_score'] = f1_score(y_test, predictions)
if grid_search:
tuning_list.append(results)
print('### BEST PARAMS ###')
display(pipe.best_params_)
else:
eval_list.append(results)
print('### METRICS ###')
display(results)
tn, fp, fn, tp = confusion_matrix(y_test, predictions).ravel()
print(f"True Negatives: {tn}")
print(f"False Positives: {fp}")
print(f"False Negatives: {fn}")
print(f"True Positives: {tp}")
return pipe
# Create list to store model testing results
eval_list = []
Numeric Classifier¶
As there were significant differences within the numerical features of the posts extracted from both subreddits (e.g. title/post length and number of comments), I wanted to test out a model with only these features. Surprisingly, this model performed pretty well and achieved a R2 score of 66.8% on the test data.
When including sentiment analysis information (compound score from VADER), this accuracy increased substantially to 71.2% on the test data. Clearly, sentiment is an important numerical feature for classifying our particular subreddit posts.
combined_df['title_len'] = len(combined_df['title'])
combined_df['selftext_len'] = len(combined_df['selftext'])
combined_df['compound'] = sentiment_df['compound']
X_bm = combined_df[['upvotes', 'n_comments', 'title_len', 'selftext_len', 'compound']]
y_bm = combined_df['is_menslib']
# Split our data into train and test data
X_bm_train, X_bm_test, y_train, y_test = train_test_split(X_bm, y_bm, test_size=0.3, stratify=y, random_state=42)
logreg = LogisticRegression()
logreg.fit(X_bm_train, y_train)
logreg.score(X_bm_train, y_train)
logreg.score(X_bm_test, y_test)
bm1_pred = logreg.predict(X_bm_test)
tn, fp, fn, tp = confusion_matrix(y_test, bm1_pred).ravel()
print("True Negatives: %s" % tn)
print("False Positives: %s" % fp)
print("False Negatives: %s" % fn)
print("True Positives: %s" % tp)
Here, True Negatives are r/MensRights posts that were correctly classified by our model. True Positives are r/MensLib posts that were correctly classified by our model.
With sentiment scores excluded, our model did particularly badly in predicting r/MensRights posts, with 116 posts from r/MensLib classified as r/MensRights posts. With sentiment scores included, the overall f-score increased from 0.67 to 0.71.
Final Model Selection¶
Due to length limitations, I'll avoid going too far into my model selection and hyperparameter tuning process. Some of the models I tried included random forest and extra trees classifiers, adaptive boost and gradient boosting classifiers, a support vector machine classifier, and finally a naive bayes multinomial classifier. I tried out various vectorizers including CountVectorizer, TfidfVectorizer and HashingVectorizer.
tuning_df = pd.DataFrame(tuning_list)
tuning_df.sort_values(by=['test', 'roc'], ascending=False).reset_index(drop=True)
After trying out various model and vectorizer combinations, it turned out that logistic regression with TfidfVectorizer returned the highest R2 accuracy -- in short, our model is able accurately predict 83.4% of the test data based on our text features. The model also has the best AUC-ROC score. We can interpret this metric as proof that that this model is the best at distinguishing between classes. The model does particularly very well in terms of recall, with only 30 false negatives (predicted r/MensRights but actually r/MensLib posts).
While the Multinomial Naive Bayes model with CountVectorizer is better at minimizing false positives (predicted r/MensLib but actually r/MensRights posts), the Logistic Regression model with TfidfVectorizer still wins overall in terms of test accuracy and f-score.
To summarize, our final model:
- uses Tfidf Vectorization with no max feature limit
- includes only words or n-grams that appear in at least 4 posts
- excludes stop words and ignores terms that that appear in more than 20% of posts
- uses Logistic Regression with Ridge regularization ($\alpha$ = 0.1 | C = 10)
Our model is still overfitting quite a bit as indicated by the large gap between training and test scores, but this seems to be the limit to which we can push our model.
AUC-ROC Curve¶
fig, ax = plt.subplots(1, 1, figsize=(12,10))
plot_roc_curve(cvec_lr_gs, X_test, y_test, ax=ax, name='LogisticRegression-CVEC(GS)', color='lightgrey')
plot_roc_curve(cvec_nb_gs, X_test, y_test, ax=ax, name='MultinomialNB-CVEC(GS)', color='lightgrey')
plot_roc_curve(tvec_svc_gs, X_test, y_test, ax=ax, name='SupportVectorClassifier-TVEC(GS)', color='lightgrey')
plot_roc_curve(tvec_lr_gs, X_test, y_test, ax=ax, name='LogisticRegression-TVEC(GS)', color='blue')
plt.plot([0, 1], [0, 1], color='black', lw=2, linestyle='--', label='Random Guess')
plt.legend()

We can see that our chosen model, Logistic Regression with TfidfVectorizer does pretty well as indicated by the AUC-ROC curve. The other classifiers all come pretty close, but it's clear that our chosen model is generally outperforming the other models at most decision thresholds, apart from the start of the curve. It also looks like the model has the best true positive to false positive threshold with a ~0.85 TPR to ~0.2 FPR.
Model Insights¶
Each post has a probability assigned to it that determines whether our model classifies it as a r/MensLib or r/MensRights post. What we can do here, is to look at these probabilities and identify the top posts that model believes to be indicative of a particular subreddit.
tvec_lr_gs.best_estimator_
coefs = pd.DataFrame(tvec_lr_gs.best_estimator_.steps[1][1].coef_).T
coefs.columns = ['coef']
coefs['ngram'] = tvec_lr_gs.best_estimator_.steps[0][1].get_feature_names()
coefs = coefs[['ngram','coef']]
coefs = coefs.sort_values('coef', ascending=True)
top_mensrights_coefs = coefs.head(15).reset_index(drop=True)
top_menslib_coefs = coefs.tail(15).sort_values(by='coef', ascending=False).reset_index(drop=True)
By looking at the coefficients from our model, we can determine the words or n-grams that are most related to r/MensLib and r/MensRights. As we assigned r/MensRights posts to 0, and r/MensLib posts to 1, words or n-grams with the lowest negative coefficients are words or n-grams that are most predictive of r/MensRight. This applies vice versa for r/MensLib. What our model has done here, is to search for words and n-grams that appear frequently in one subreddit relative to the other.
plt.figure(figsize=(10,10))
sns.barplot(data=top_mensrights_coefs, x=-top_mensrights_coefs['coef'], y='ngram', palette='Reds_r')
plt.ylabel('')
plt.title('Top 15 Ngrams Correlated with r/MensRights', fontsize=20);

There are extremely strong correlations around the terms feminists, feminism, female and feminist. This makes sense, given that the men's rights movement largely believes that feminism harms men by concealing discrimination and promoting gynocentrism. The top few words from the sub are therefore focused around the loss of rights, and a push towards 'equality'. For r/MensRights, the case of Johnny Depp and Amber Heard represents a percieved 'imbalance of power' between sexes, and serves to reinforce their belief that men are victims.
We also see other areas where r/MensRights belives that men are disadvantaged -- in terms of court cases and the issue of male circumcision. The International Conference on Men's Issues is also a point of interest here. It represents men coming together to take on the so-called 'specter' of feminism.
plt.figure(figsize=(10,10))
sns.barplot(data=top_menslib_coefs, x=top_menslib_coefs['coef'], y='ngram', palette='Blues_r')
plt.xticks(np.arange(0, 6, step=1))
plt.ylabel('')
plt.title('Top 15 Ngrams Correlated with r/MensLib', fontsize=20);

r/MensLib is much more focused on masculinity as compared to feminism. We see that mentions of feminism aren't central here, which makes sense given that r/MensLib is a pro-feminism sub that focuses on how masculinity, particularly toxic masculinity can harm both men and women. The spectrum that these words cover seems to quite broad, covering boys and men, including trans and gay men.
We can also see that relative to r/MensRights,r/MensLib is much more focused on inter-personal relationships and personal issues.
Predictive Wordclouds¶
def plot_cloud(wordcloud):
plt.figure(figsize=(20, 14))
plt.imshow(wordcloud)
plt.axis("off");
menslib_posts = list(combined_df[combined_df['is_menslib'] == 1]['combi_text'])
mensrights_posts = list(combined_df[combined_df['is_menslib'] == 0]['combi_text'])
menslib_wordcloud = WordCloud(
width = 2000, height = 2000, random_state = 42,
background_color = 'white',colormap='Blues',
max_font_size = 900).generate(' '.join(menslib_posts))
plot_cloud(menslib_wordcloud)
plt.title('r/MensLib', fontsize=30)
#plt.savefig('MensLib', dpi=300)

mensrights_wordcloud = WordCloud(
width = 2000, height = 2000, random_state = 42,
background_color = 'white',colormap='Reds',
max_font_size = 900).generate(' '.join(mensrights_posts))
plot_cloud(mensrights_wordcloud)
plt.title('r/MensRights', fontsize=30)

predictions = pd.DataFrame(tvec_lr_gs.predict_proba(X))
predictions['combi_text'] = combined_df['combi_text']
predictions.columns = ['mensrights', 'menslib', 'combi_text']
Top Predicted Posts¶
# Top predicted r/mensrights posts
predictions.sort_values('mensrights', ascending=False)[:15]
We can see that our model has a pretty good grasp on typical r/MensRights posts here. Posts that include mention of Johnny Depp or Amber Heard are strongly predicted as r/MensRights posts, along with anything mentioning feminism or international men's day.
# Top predicted r/menslib posts
predictions.sort_values('menslib', ascending=False)[:15]
We see that strongly predicted r/MensLib posts are posts that involve mention of the LGBTQ community -- this suggests that discussion of men/LGBTQ issues are largely absent from r/MensRights. We can probably assume that that subreddit doesn't have a particularly intersectional community.
# False positives -- posts that model wrongly classified as r/menslib
wrong_predictions[(wrong_predictions['menslib'] > 0.85) & (wrong_predictions['pred'] == 1)]
for i in combined_df['og_text']:
print_post('hour shifts', i)
for i in combined_df['og_text']:
print_post('old dad opened', i)
# False negatives -- posts that model wrongly classified as r/mensrights
wrong_predictions[wrong_predictions['mensrights'] > 0.85]
for i in combined_df['og_text']:
print_post('the trial of johnny depp', i)
Model Limitations¶
As demonstrated by the false predictions above, our model does have some limitations, especially when it comes to predicting r/MensRights posts. Mentioning mental health throws off our model, even though it could potentially be an issue pertinent to r/MensRights. When it comes to the wire, both groups care deeply about similar issues facing men (e.g. male suicide, male parenting, male genital cutting), even if their approach and beliefs are fundamentally different. Similarly, mentions of Amber Heard and Johnny Depp are disproportionately weighted and can easily throw the model off.
I also wouldn't be surprised if r/MensLib is sometimes critical of certain branches of feminism or feminists that espouse hate towards men as an entire group.
In today's day and age, gender issues continue to be extremely complicated, and even a well-trained model will still struggle to differentiate men and their beliefs that exist across a wide spectrum.
To further improve model accuracy, we'd ideally need to train our model to recognize slightly more abstract concepts such as the level of introspection or sentiment within the post. This would allow our model to deal with issues that are topical to r/MensRights (e.g. Johnny Depp and Amber Heard), but classify posts not just by mention of a name, but also by syntactic patterns that suggest introspection such as like 'I have been thinking' or 'I'd love to hear people's views'.
Recommendations¶
Beyond easing the burden of moderators by giving them the ability to classify posts from two different subreddits based on their title and selftext, there are several other possible applications for this model.
By looking at the probabilities associated with each post, moderators can also understand the overall direction of their subreddit. It's often hard to trace the evolution of subreddits over time, however, by looking at the posts that have an extremely high classification probability (>0.99), moderators can see the language and topics that have become characteristic or emblematic of their community.
Depending on their objectives, moderators can then try to increase the diversity of topics within their subreddit, or try to attempt to refocus conversations that are straying from the vision and objectives of the subreddit.
The sentiment analysis we implemented could also be useful here moderators. For example, the moderators from r/MensLib are focused on maintaining positive and constructive discourse. Armed with the ability to monitoring changes in sentiment over time, the moderation team can determine the overall 'mood' of their community and proactively work to address points of potential conflict within the community.